
Wir gratulieren Prof. Belagiannis und Alexander Tsaregorodtsev zu ihrem Journalbeitrag mit dem Namen „ParticleAugment: Sampling-based data augmentation“ Die Datenvermehrung, oder data augmentation (DA) auf Englisch, wird beim Training eines neuronalen Netzes eingesetzt, um Überanpassung zu vermeiden. Außerdem kann ein Netzwerk dadurch besser verallgemeinern. Im Grunde kann die DA manuell und speziell für jedes Netzwerk und jede Trainingsmethode eingesetzt werden, jedoch werden in letzter Zeit mehr und mehr automatische Methoden entwickelt. Solche automatischen Methoden haben zum Ziel, optimale Regeln für die DA zu generieren, um erstens die Leistung des Netzwerks zu erhöhen und zweitens um zu vermeiden, dass manuell eine DA durchgeführt werden muss. 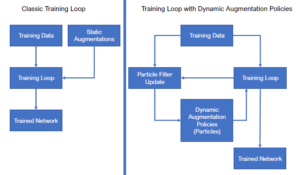
In dem hier beschriebenen Paper wird „ParticleAugment (PA)“ vorgestellt. PA basiert auf der Idee der Partikelfilterung für neuronale Netze. Hierzu werden optimale Regeln für eine DA durch eine Wahrscheinlichkeitsdichtefunktion repräsentiert, die durch einen Satz Partikel beschrieben wird. Während des Trainings werden die Partikel verrauscht und anhand eines Fehlermaßes evaluiert. Anschließend werden die Gewichte der Partikel angepasst und eine optimierte Verteilungsdichte berechnet. Nach der Neuberechnung der Partikel werden schließlich neue Daten anhand der Verteilung generiert und das Netzwerk hiermit trainiert. Durch diese Methode können wir die Leistung des Netzwerks signifikant verbessern und den Rechenaufwand für die DA minimieren.