Videokommunikation
Unser Lehrstuhl beschäftigt sich mit einer Vielzahl an Themen rund um die Videokompression. Dabei erforschen wir aktuelle Videocodierstandards wie HEVC und entwickeln neue Kompressionsmethoden für zukünftige Codecs wie VVC. Zusätzlich betrachten wir völlig neue Codieransätze für spezielle Inhalte wie Medizindatensätze, computergenerierte Videos, Fisheye- und 360°-Videodaten.
Codierung mit Hilfe des Machine Learning
Videocodierung für maschinelle Kommunikation basierend auf tiefem Lernen
| Ihr Ansprechpartner |
| Marc Windsheimer, M.Sc. |
| E-Mail: marc.windsheimer@fau.de |
| Link zur Person |
Üblicherweise sind aktuelle Videocodecs auf das menschliche Wahrnehmungsvermögen ausgelegt und optimiert. Allerdings gewinnt die sogenannte Maschine-zu-Maschine (M2M) Kommunikation immer mehr an Bedeutung, bei denen maschinelle Algorithmen das resultierende komprimierte Videosignal analysieren, um damit bestimmte Aufgaben erfüllen zu können. Diese Aufgaben erstrecken sich von der Automatisierung industrieller Prozesse, der Überwachung von öffentlichen Orten bis hin zum autonomen Fahren von Autos. Bei solchen Szenarien ist dann nicht mehr die subjektive visuelle Qualität für den Menschen maßgeblich, sondern die Detektionsrate des Algorithmus. Bei den Algorithmen, die final die Qualität der Codierung bewerten, wird der Fokus auf neuronale Objektdetektionnetzwerke (R-CNNs) gelegt
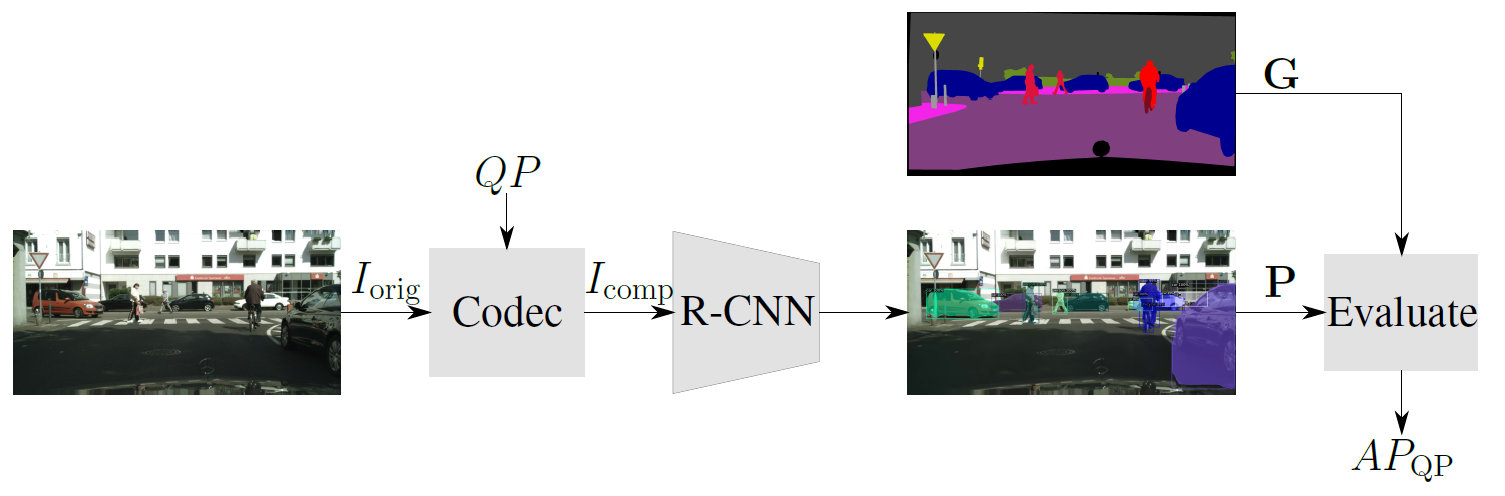
Die entscheidende Frage für die Videokompression in der M2M-Kommunikation ist nun, wie stark die Originaldaten komprimiert werden können, um immer noch ein zufriedenstellendes Dektionsergebnis zu bekommen. Außerdem kann hier die Frage gestellt werden, ob andere Ansätze für den Videocodec verwendet werden sollten, um ein möglichst optimales Verhältnis aus Kompressions- und Detektionsrate zu erlangen.
Deep Learning für Videocodierung
Conditional Inter Frame Coding
| Ihr Ansprechpartner |
| Fabian Brand, M.Sc. |
| E-Mail: fabian.brand@fau.de |
| Link zur Person. |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link zur Person. |
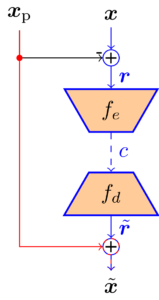
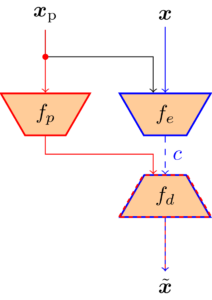
Der Einsatz neuraler Netze macht die Videokompression deutlich flexibler, da zugrundeliegende Statistiken und Wahrscheinlichkeitsfunktionen direkt aus den Daten gelernt werden können, während traditionelle Videocoder auf händisch designten Transformationen und Statistiken beruhen. Gegenstand dieses Forschungsbereiches ist die Anwendung von sogenanntem Conditional Inter Frame Coding. Dieser Ansatz löst das Problem der prädizierten Übertragung eines Frames in einem Video. Um zeitliche Redundanz auszunutzen liegt ein Prädiktionssignal, welches aus dem vorherigen Frame generiert wird vor. Traditionell wird dieses Prädiktionssignal von dem aktuellen Frame subtrahiert und das Differenzbild wird übertragen bevor es auf der Decoderseite wieder auf das Prädiktionssignal addiert wird. Mithilfe der Informationstheorie lässt sich jedoch zeigen, dass dieser Weg nicht optimal ist. Es ist wesentlich besser, den aktuellen Frame unter der Bedingung, dass das Prädiktionssignal bekannt ist zu übertragen. Einen solchen conditional Coder umzusetzen ist mit traditionellen Methoden jedoch nur sehr schwer möglich. Neuronale Netze hingegen können die entsprechende Statistik jedoch direkt lernen.
In diesem Bereich erforschen wir die theoretischen und praktischen Eigenschaften einen Conditional Inter Frame Coders. Fokus liegt hier auf der Beschreibung, Modellierung und Behebung von sogenannten Information Bottlenecks, die bei conditional Codern auftreten und die Leistung schmälern können.
|
Residual Coder
|
Conditional Coder
|
End-to-End optimierte Bild- und Videocodierung
| Ihr Ansprechpartner |
| Anna Meyer, M.Sc. |
| E-Mail: anna.meyer@fau.de |
| Link zur Person |
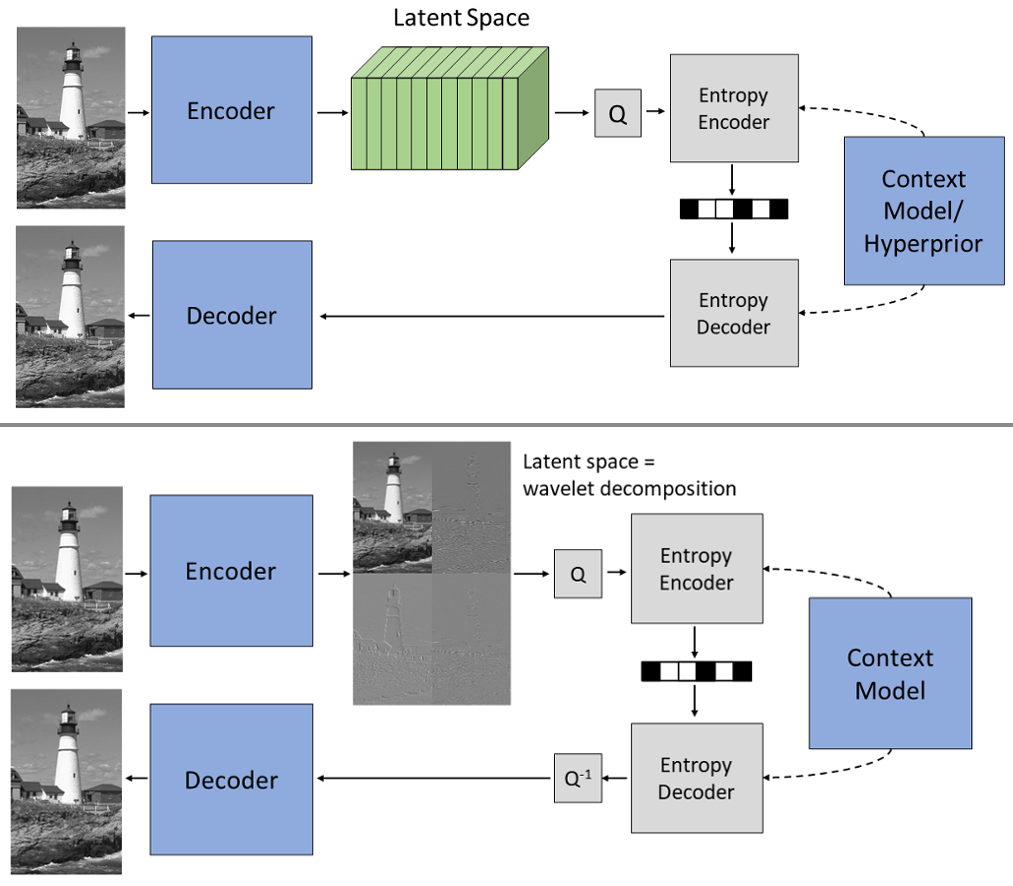
In letzter Zeit wurden verschiedene Komponenten von Videocodern erfolgreich mit neuronalen Netzen verbessert. Diese Ansätze beruhen jedoch auf separat entwickelten und optimierten Modulen. End-to-End-optimierte Bild- und Videocodierung ist ein aktuelles Forschungsgebiet, das eine gemeinsame Optimierung des gesamten Codierungssystems ermöglicht. Die beliebtesten Ansätze basieren dabei auf komprimierenden Autoencodern: Der Encoder berechnet eine sogenannte Latent Space Repräsentation, die anschließend quantisiert und mittels Entropiecodierung verlustfrei komprimiert wird. Anschließend berechnet der Decoder das rekonstruierte Bild oder Video ausgehend vom quantisiertem Latent Space.
Dabei hat sich gezeigt, dass der Latent Space redundante Informationen enthält, die z. B. durch ein örtliches Kontextmodell oder sogenanntes Channel Conditioning reduziert werden können. Mögliche weitere Redundanz auszunutzen ist wegen der fehlenden Interpretierbarkeit des Latent Space jedoch eine Herausforderung.
Ein interessanter Ansatz ist deswegen, Encoder und Decoder nach dem Lifting Schema aufzubauen. Dadurch erzeugt der Encoder einen Latent Space, der eine gelernte Wavelet-Zerlegung darstellt. Dieses Wissen über die Struktur des Latent Space erleichtert die Entwicklung effizienter lernbasierter Verfahren für die Bild- und Videokompression. Außerdem können Ansätze aus der klassischen Wavelet-Kompression übernommen werden.
Energieeffiziente Videokommunikation
Heutzutage wird die Videokommunikation weltweit von Milliarden von Nutzern verwendet. Die zugehörigen Applikationen werden auf verschiedensten Geräten durchgeführt, zum Beispiel Handys, Notebooks oder Fernseher. Eine aktuelle Studie hat in diesem Zusammenhang gezeigt, dass 1% der Treibhausgasemissionen durch Videokommunikationsanwendungen verursacht wird (Link). Hierin enthalten sind alle Faktoren wie die Aufnahme, die Speicherung, die Kompression, die Decodierung und die Übertragung der Videodaten. Aufgrund dieses hohen Anteils und dem prognostizierten Wachstum ist es sehr wichtig, den tatsächlichen Energieverbrauch aller dieser Systeme zu erforschen, um für die Zukunft neue, energieeffiziente Lösungen entwickeln zu können.
![]()
Daher beschäftigen wir uns in diesem Forschungsthema mit der energieffizienten Videokommunikation. Dazu haben wir in den letzten Jahren verschiedenste Messaufbauten entwickelt, um Hardwaremodule wie Handys, Evaluationsboards, einzelne Chips oder PCs energetisch zu vermessen. Mit Hilfe dieser Daten entwickeln wir extrem genaue Energie- und Leistungsmodelle, die den Verbrauch während der Ausführung akkurat und verlässlich schätzen. Die Modelle werden schließlich dafür eingesetzt, neuartige und energieeffiziente Methoden vorzuschlagen und zu entwickeln.
Für die Zukunft wollen noch tiefer in die Thematik einsteigen und alle Komponenten im Detail betrachten, die in der Videokommunikation verwendet werden. Aktuell arbeiten wir an Themen wie die Übertragung der Videos, 360°-Videos, die Codierung und neue Videocodecs. Wir suchen stets nach neuen Themen und sind offen für interessante Abschlussarbeiten, Kollaborationen oder anderen Ideen.
Energieeffiziente Videocodierung
| Ihr Ansprechpartner |
| Matthias Kränzler, M.Sc. |
| E-Mail: matthias.kraenzler@fau.de |
| Link zur Person |
In den letzten Jahren steigen die Menge und der Anteil an Videodaten im globalen Internetdatenverkehr stetig an. Sowohl die Encodierung auf der Senderseite, als auch die Decodierung auf der Empfängerseite benötigen viel Energie. Forschung zu energieeffizienter Videodecodierung hat gezeigt, dass es möglich ist den Energiebedarf der Decodierung zu optimieren. Dieses Arbeitsgebiet beschäftigt sich mit der Modellierung der Energie, die für die Encodierung von komprimierten Videodaten notwendig ist. Ziel der Modellierung ist die Optimierung der Energieeffizienz der gesamten Videocodierung.

„Big Buck Bunny“ by Big Buck Bunny is licensed under CC BY 3.0
Energieeffiziente Videodekommunikation
| Ihr Ansprechpartner |
| Dr.-Ing. Christian Herglotz |
| E-Mail: christian.herglotz@fau.de |
| Link zur Person |
Dieses Arbeitsgebiet beschäftigt sich mit der energieeffizienten Decodierung von komprimierten Videodaten. Die Decodierung ist insbesondere für batteriebetriebene Geräte wie Smartphones oder Tablet PCs von Bedeutung, die z.B. bei mobilen Videostreaminganwendungen viel Energie benötigen.
Durch ausgeklügelte Algorithmen und Methoden kann dieser Energieverbrauch gesenkt werden, ohne dass die visuelle Qualität der Sequenzen leidet. Hierzu wurde in unserer Arbeit zuerst ein Modell erstellt, mit dem der Energieverbrauch eines Decoders anhand von Bitstrommerkmalen akkurat geschätzt werden kann. Die Energie lässt sich dann den Bitstrommerkmalen zuordnen und visualisieren.
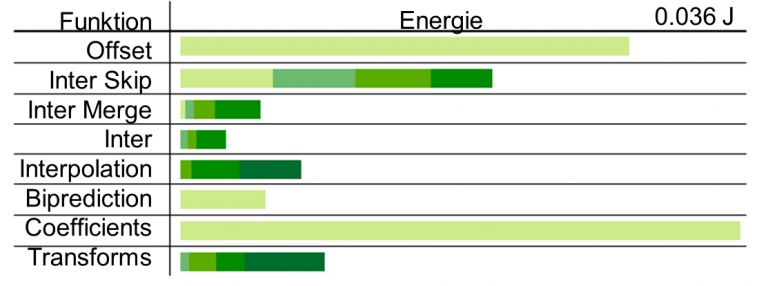

Ein entsprechender Coder, der dieses Modell ausnutzt, um energieeffiziente Bitströme zu generieren, kann auf folgender Seite heruntergeladen werden:
Decoding-Energy-Rate-Distortion Optimization (DERDO) for Video Coding
Codierung von Ultraweitwinkel- und 360°-Videodaten
Projektionsbasierte Videocodierung
| Ihr Ansprechpartner |
| Andy Regensky, M.Sc. |
| E-Mail: andy.regensky@fau.de |
| Link zur Person |
Ultraweitwinkel- und 360°-Videodaten unterliegen einer Vielzahl von Verzerrungen, welche bei herkömmlichen Videomaterial, das mit perspektivischen Objektiven aufgenommen wurde, nicht vorkommen. Diese Verzerrungen entstehen vor allem, da Ultraweitwinkelobjektive nicht dem Lochkameramodell folgen und somit spezielle Bildcharakteristiken vorliegen. Deutlich wird dies zum Beispiel dadurch, dass gerade Linien auf dem Bildsensor gebogen abgebildet werden. Nur so, sind Sichtfelder von 180° und mehr mit nur einer Kamera realisierbar. Mittels sogenannter Stitching-Verfahren können mehrere Kameraansichten zu 360°-Aufnahmen kombiniert werden, die eine komplette Rundumsicht ermöglichen. Häufig wird dies durch den Einsatz von zwei Ultraweitwinkelkameras realisiert, wobei jede Kamera eine Halbkugel aufnimmt. Um die entstehenden sphärischen 360°-Aufnahmen mit Hilfe bestehender Videocodecs komprimieren zu können, müssen die Aufnahmen auf die zweidimensionale Bildfläche projiziert werden. Hierbei kommen verschiedene Abbildungsfunktionen zum Einsatz. Häufig fällt die Wahl auf das Equirectangular-Format, welches vergleichbar mit der Darstellung des Globus auf einer Weltkarte ist, und somit 360° in horizontaler, sowie 180° in vertikaler Richtung abbildet.
Da herkömmliche Videocodecs nicht auf die von der perspektivischen Projektion abweichenden Abbildungsformate abgestimmt sind, kommt es zu Verlusten, die durch eine Berücksichtigung der vorliegenden Projektionsformate vermindert werden können. In diesem Projekt werden daher verschiedene Codieraspekte untersucht und im Hinblick auf die vorkommenden Projektionen bei Ultraweitwinkel- und 360°-Videodaten optimiert. Ein spezieller Fokus liegt dabei auf der projektionsbasierten Bewegungskompensation, sowie der Intraprädiktion.

Screen Content Codierung
Screen Content Codierung basierend auf maschinellem Lernen und statistischer Modellierung
| Ihr Ansprechpartner |
| Hannah Och, M.Sc. |
| E-Mail: hannah.och@fau.de |
| Link zur Person |
In den letzten Jahren erfährt die Verarbeitung von sogenanntem screen content immer mehr Aufmerksamkeit. Screen Content steht dabei für Bilder, welche typischerweise auf Displays von Arbeitsplatzrechnern, Smartphones oder Ähnlichem zu sehen sind. Dabei sind die statistischen Eigenschaften von Screen-Content-Bildern oder Sequenzen sehr divers. Solche Bilder enthalten im Allgemeinen ’synthetische‘ Bildinhalte, nämlich Strukturen wie Buttons, Grafiken, Diagramme, Symbole, Texte, usw., welche besonders durch zwei bedeutende Eigenschaften gekennzeichnet sind: eine begrenzte Auswahl an Farben sowie sich wiederholende Muster. Neben den genannten Strukturen sind jedoch auch ’natürliche‘ Inhalte in Screen-Content inbegriffen, etwa Fotos und Videosequenzen, medizinische Aufnahmen oder computergenerierte fotorealistische Animationen. Anders als synthetische Aufnahmen sind diese durch unregelmäßige Farbverläufe und einen gewissen Rauschanteil gekennzeichnet. Screen Content ist typischerweise eine Mischung aus natürlichem und synthetischen Inhalten. Die Übertragung eben solcher Bildern und Sequenzen wird für eine Vielzahl von Anwendungen benötigt, wie etwa Screen Sharing, Cloud Computing oder Gaming.
Allerdings stellt Screen Content für herkömmliche Codierungsverfahren eine Herausforderung dar, da diese auf natürliche Inhalte optimiert sind und deshalb Screen-Content nicht effizient komprimieren können. Daher konzentriert sich dieses Projekt auf Weiterentwicklung und Testung einer neuen Kompressionsmethode für verlustlose und nahezu-verlustlose bzw. verlustbehafteter Kompression von Screen-Content-Inhalten. Ein besonderer Schwerpunkt wird dabei auf eine Kombination von maschinellem Lernen und statistischer Modellierung gelegt.
2024
- , , , , , , , , , , :
The Bjøntegaard Bible - Why your Way of Comparing Video Codecs May Be Wrong
In: IEEE Transactions on Image Processing 33 (2024), S. 987 - 1001
ISSN: 1057-7149
DOI: 10.1109/TIP.2023.3346695
BibTeX: Download - , , , :
Enhanced Color Palette Modeling for Lossless Screen Content Compression
2024 IEEE International Conference on Acoustics, Speech and Signal Processing (Seoul, 14. April 2024 - 19. April 2024)
DOI: 10.1109/ICASSP48485.2024.10446445
URL: https://arxiv.org/abs/2312.14491
BibTeX: Download - , , , :
Improved Screen Content Coding in VVC Using Soft Context Formation
2024 IEEE International Conference on Acoustics, Speech and Signal Processing (Seoul, 14. April 2024 - 19. April 2024)
DOI: 10.1109/ICASSP48485.2024.10447125
URL: https://arxiv.org/abs/2305.05440
BibTeX: Download - , , :
Analysis of Neural Video Compression Networks for 360-Degree Video Coding
Picture Coding Symposium (PCS) (Taichung, 12. Juni 2024 - 14. Juni 2024)
BibTeX: Download - , :
Geometry-Corrected Geodesic Motion Modeling with Per-Frame Camera Motion for 360-Degree Video Compression
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (Seoul, 14. April 2024 - 19. April 2024)
DOI: 10.1109/ICASSP48485.2024.10446915
URL: https://arxiv.org/abs/2312.09266
BibTeX: Download
2023
- , , , , :
Processing Energy Modeling for Neural Network Based Image Compression
accepted for IEEE International Conference on Image Processing (ICIP) (Kuala Lumpur, 8. Oktober 2023 - 11. Oktober 2023)
URL: https://arxiv.org/abs/2306.16755
BibTeX: Download - , , , :
Video Decoding Energy Reduction Using Temporal-Domain Filtering
First International Workshop on Green Multimedia Systems (GMSys '23) on the ACM Multimedia Systems (MMSys) (Vancouver, 7. Juni 2023 - 10. Juni 2023)
DOI: 10.1145/3593908.3593948
URL: https://arxiv.org/abs/2306.06917
BibTeX: Download - , , , , :
Energy Efficiency in Video Compression
In: IEEE MMTC Communications - Frontiers 18 (2023), S. 8-14
Open Access: https://site.ieee.org/comsoc-mmctc/files/2023/10/MMTC-May-2023-18_3.pdf
BibTeX: Download - , , , :
Sweet Streams are Made of This: The System Engineer’s View on Energy Efficiency in Video Communications (Preprint)
In: Ieee Circuits and Systems Magazine 23 (2023), S. 57-77
ISSN: 1531-636X
DOI: 10.1109/MCAS.2023.3234739
BibTeX: Download - , , , , :
Power Reduction Opportunities on End-User Devices in Quality-Steady Video Streaming
15th International Conference on Quality of Multimedia Experience (QoMEX) (Gent, 20. Juni 2023 - 22. Juni 2023)
DOI: 10.48550/arXiv.2305.15117
URL: https://arxiv.org/abs/2305.15117
BibTeX: Download - , , :
Motion Plane Adaptive Motion Modeling for Spherical Video Coding in H.266/VVC
IEEE International Conference on Image Processing (ICIP) (Kuala Lumpur, 8. Oktober 2023 - 11. Oktober 2023)
DOI: 10.1109/ICIP49359.2023.10222661
URL: https://arxiv.org/abs/2306.13694
BibTeX: Download - , , , :
Image Segmentation for Improved Lossless Screen Content Compression
2023 IEEE International Conference on Acoustics, Speech and Signal Processing (Rhode Islands, Greece, 4. Juni 2023 - 10. Juni 2023)
DOI: 10.1109/ICASSP49357.2023.10094983
URL: https://ieeexplore.ieee.org/document/10094983
BibTeX: Download
2022
- , , , , :
Evaluation of Video Coding for Machines Without Ground Truth
2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Singapore, 22. Mai 2022 - 27. Mai 2022)
DOI: 10.1109/ICASSP43922.2022.9747633
URL: https://arxiv.org/abs/2205.06519
BibTeX: Download - , , :
Rate-Distortion Optimal Transform Coefficient Selection for Unoccupied Regions in Video-Based Point Cloud Compression
In: IEEE Transactions on Circuits and Systems For Video Technology (2022), S. 1-1
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2022.3185026
URL: https://arxiv.org/abs/2206.12186
BibTeX: Download - , , , :
Beyond Bjontegaard: Limits of Video Compression Performance Comparisons
IEEE International Conference on Image Processing (Bordeaux, 17. Oktober 2022 - 19. Oktober 2022)
DOI: 10.1109/ICIP46576.2022.9897912
BibTeX: Download - , , , , :
Modeling of Energy Consumption and Streaming Video QoE using a Crowdsourcing Dataset
The 14th International Conference on Quality of Multimedia Experience (QoMEX) (Lippstadt, 5. September 2022 - 7. September 2022)
DOI: 10.1109/QoMEX55416.2022.9900886
BibTeX: Download - , , :
Energy Efficient Video Decoding for VVC Using a Greedy Strategy Based Design Space Exploration
In: IEEE Transactions on Circuits and Systems For Video Technology 32 (2022), S. 4696-4709
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2021.3130739
URL: https://arxiv.org/abs/2111.12194
BibTeX: Download - , , :
Modeling the HEVC Encoding Energy Using the Encoder Processing Time
IEEE International Conference on Image Processing (ICIP) 2022 (Bordeaux, 16. Oktober 2022 - 19. Oktober 2022)
DOI: 10.1109/ICIP46576.2022.9897306
URL: http://arxiv.org/abs/2207.02676
BibTeX: Download - , , :
A Bit Stream Feature-Based Energy Estimator for HEVC Software Encoding
Picture Coding Symposium (PCS 2022) (San Jose, California, 7. Dezember 2022 - 9. Dezember 2022)
DOI: 10.1109/PCS56426.2022.10018048
URL: https://arxiv.org/abs/2212.05609
BibTeX: Download
2021
- , , :
Editorial to the Special Section on Optimized Image/Video Coding Based on Deep Learning
In: IEEE Open Journal of Circuits and Systems 2 (2021), S. 611 - 612
ISSN: 2644-1225
DOI: 10.1109/OJCAS.2021.3124408
BibTeX: Download - , , , :
Robust Deep Neural Object Detection and Segmentation for Automotive Driving Scenario with Compressed Image Data
IEEE International Symposium on Circuits and Systems (ISCAS) (Daegu (Virtual Conference), 23. Mai 2021 - 25. Mai 2021)
DOI: 10.1109/ISCAS51556.2021.9401621
URL: https://arxiv.org/abs/2205.06501
BibTeX: Download - , , , :
Saliency-Driven Versatile Video Coding for Neural Object Detection
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Toronto (Virtual Conference), 6. Juni 2021 - 11. Juni 2021)
DOI: 10.1109/ICASSP39728.2021.9415048
URL: https://arxiv.org/abs/2203.05944
BibTeX: Download - , , , :
Analysis of Neural Image Compression Networks for Machine-to-Machine Communication
IEEE International Conference on Image Processing (ICIP) (Anchorage (virtual), 19. September 2021 - 22. September 2021)
DOI: 10.1109/ICIP42928.2021.9506763
URL: https://arxiv.org/abs/2205.06511
BibTeX: Download - , , :
Optimization of Probability Distributions for Residual Coding of Screen Content
2021 IEEE International Conference on Visual Communications and Image Processing (VCIP) (München, 5. Dezember 2021 - 8. Dezember 2021)
DOI: 10.1109/VCIP53242.2021.9675326
URL: https://arxiv.org/abs/2212.01122
BibTeX: Download - , , :
A Novel Viewport-Adaptive Motion Compensation Technique for Fisheye Video
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Toronto, 6. Juni 2021 - 11. Juni 2021)
DOI: 10.1109/ICASSP39728.2021.9413576
URL: https://arxiv.org/abs/2202.13892
BibTeX: Download
2020
- , , , :
Video Coding for Machines with Feature-Based Rate-Distortion Optimization
IEEE International Workshop on Multimedia Signal Processing (MMSP) (Tampere (Virtual Conference), 21. September 2020 - 24. September 2020)
DOI: 10.1109/MMSP48831.2020.9287136
URL: https://arxiv.org/abs/2203.05890
BibTeX: Download - , , :
On Intra Video Coding and In-loop Filtering for Neural Object Detection Networks
IEEE International Conference on Image Processing (ICIP) (Abu Dhabi (virtual Conference), 25. Oktober 2020 - 28. Oktober 2020)
DOI: 10.1109/ICIP40778.2020.9191023
URL: https://arxiv.org/abs/2203.05927
BibTeX: Download - , , , :
Decoding Energy Optimal Video Encoding for x265
IEEE 22nd Workshop on Multimedia Signal Processing (MMSP) (Tampere, 21. September 2020 - 23. September 2020)
DOI: 10.1109/MMSP48831.2020.9287054
BibTeX: Download - , , , , , :
Power Modeling for Video Streaming Applications on Mobile Devices
In: IEEE Access (2020)
ISSN: 2169-3536
DOI: 10.1109/ACCESS.2020.2986580
BibTeX: Download - , , :
Matched Quality Evaluation of Temporally Downsampled Videos with Non-Integer Factors
International Conference on Quality of Multimedia Experience (QoMEX) (Athlone, 26. Mai 2020 - 28. Mai 2020)
DOI: 10.1109/QoMEX48832.2020.9123084
BibTeX: Download - , , :
DENESTO: A Tool for Video Decoding Energy Estimation and Visualization
2020 IEEE International Conference on Visual Communications and Image Processing (VCIP) (Virtual Conference, 1. Dezember 2020 - 4. Dezember 2020)
DOI: 10.1109/VCIP49819.2020.9301877
BibTeX: Download - , , :
Decoding Energy Modeling for Versatile Video Coding
IEEE International Conference on Image Processing (ICIP) (Abu Dhabi, 25. Oktober 2020 - 28. Oktober 2020)
DOI: 10.1109/ICIP40778.2020.9190840
URL: https://doi.org/10.48550/arXiv.2209.10266
BibTeX: Download - , , :
A Comparative Analysis of the Time and Energy Demand of Versatile Video Coding and High Efficiency Video Coding Reference Decoders
IEEE International Workshop on Multimedia Signal Processing (MMSP) (Tampere, Finland, 21. September 2020 - 23. September 2020)
DOI: 10.1109/MMSP48831.2020.9287098
URL: https://arxiv.org/abs/2209.10283
BibTeX: Download - , :
Graph-Based Compensated Wavelet Lifting for Scalable Lossless Coding of Dynamic Medical Data
In: IEEE Transactions on Image Processing 29 (2020), S. 2439 - 2451
ISSN: 1057-7149
DOI: 10.1109/TIP.2019.2947138
BibTeX: Download - , , :
Multispectral Image Compression Based on HEVC Using Pel-Recursive Inter-Band Prediction
IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP) (Tampere, 21. September 2020 - 24. September 2020)
DOI: 10.1109/MMSP48831.2020.9287132
URL: https://arxiv.org/abs/2303.05132
BibTeX: Download - , , :
FishUI: Interactive Fisheye Distortion Visualization
IEEE International Conference on Visual Communications and Image Processing (VCIP) (Macau, 1. Dezember 2020 - 4. Dezember 2020)
DOI: 10.1109/VCIP49819.2020.9301754
BibTeX: Download
2019
- , , :
Intra Frame Prediction for Video Coding Using a Conditional Autoencoder Approach
Picture Coding Symposium (PCS) (Ningbo, 12. November 2019 - 15. November 2019)
DOI: 10.1109/PCS48520.2019.8954546
BibTeX: Download - , , , :
Power Modeling for Virtual Reality Video Playback Applications
IEEE 23rd International Symposium on Consumer Technologies (ISCT) (Ancona, 19. Juni 2019 - 21. Juni 2019)
DOI: 10.1109/ISCE.2019.8901018
BibTeX: Download - , , :
Decoding-Energy-Rate-Distortion Optimization for Video Coding
In: IEEE Transactions on Circuits and Systems For Video Technology 29 (2019), S. 171-182
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2017.2771819
BibTeX: Download - , , , , :
Efficient Coding Of 360° Videos Exploiting Inactive Regions in Projection Formats
IEEE International Conference on Image Processing (ICIP) (Taipei, 22. September 2019 - 25. September 2019)
DOI: 10.1109/ICIP.2019.8803759
BibTeX: Download - , , , :
Power-Efficient Video Streaming on Mobile Devices Using Optimal Spatial Scaling
IEEE International Conference on Consumer Electronics (ICCE) (Berlin, 8. September 2019 - 11. September 2019)
DOI: 10.1109/ICCE-Berlin47944.2019.8966177
BibTeX: Download - , :
Improving the Rate-Distortion Model of HEVC Intra by Integrating the Maximum Absolute Error
IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP) (Brighton, UK, 12. Mai 2019 - 17. Mai 2019)
DOI: 10.1109/icassp.2019.8683418
BibTeX: Download - , , :
Extending Video Decoding Energy Models for 360° and HDR Video Formats in HEVC
Picture Coding Symposium (PCS) (Ningbo, 12. November 2019 - 15. November 2019)
DOI: 10.1109/PCS48520.2019.8954563
URL: https://doi.org/10.48550/arXiv.2209.10268
BibTeX: Download - , , :
Content Adaptive Wavelet Lifting for Scalable Lossless Video Coding
IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP) (Brighton, UK, 12. Mai 2019 - 17. Mai 2019)
DOI: 10.1109/icassp.2019.8682415
BibTeX: Download - , , :
Scalable Lossless Coding of Dynamic Medical CT Data Using Motion Compensated Wavelet Lifting with Denoised Prediction and Update
Picture Coding Symposium (PCS) (Ningbo, 12. November 2019 - 15. November 2019)
DOI: 10.1109/pcs48520.2019.8954530
BibTeX: Download
2018
- , , :
Spectral Constrained Frequency Selective Extrapolation for Rapid Image Error Concealment
25th International Conference on Systems, Signals and Image Processing (IWSSIP) (Maribor, 20. Juni 2018 - 22. Juni 2018)
DOI: 10.1109/iwssip.2018.8439150
BibTeX: Download - , :
Decoding Energy Estimation of an HEVC Hardware Decoder
IEEE International Symposium on Circuits and Systems (ISCAS) (Florenz, 27. Mai 2018 - 30. Mai 2018)
DOI: 10.1109/ISCAS.2018.8350964
BibTeX: Download - , , :
Decoding Energy Modeling for the Next Generation Video Codec Based on JEM
Picture Coding Symposium (PCS) (San Francisco, 24. Juni 2018 - 27. Juni 2018)
DOI: 10.1109/pcs.2018.8456244
BibTeX: Download - , , , , , , :
Improving HEVC Encoding of Rendered Video Data Using True Motion Information
20th IEEE International Symposium on Multimedia (ISM) (Taichung, 10. Dezember 2018 - 12. Dezember 2018)
DOI: 10.1109/ism.2018.00063
URL: http://arxiv.org/abs/2309.06945
BibTeX: Download - , , , , :
Modeling the Energy Consumption of the HEVC Decoding Process
In: IEEE Transactions on Circuits and Systems For Video Technology 28 (2018), S. 217-229
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2016.2598705
BibTeX: Download - , :
Joint Optimization of Rate, Distortion, and Maximum Absolute Error for Compression of Medical Volumes Using HEVC Intra
Picture Coding Symposium (San Francisco, CA, 24. Juni 2018 - 27. Juni 2018)
DOI: 10.1109/pcs.2018.8456282
BibTeX: Download - , , , :
Compression of Dynamic Medical CT Data Using Motion Compensated Wavelet Lifting with Denoised Update
Picture Coding Symposium (San Francisco, CA, 24. Juni 2018 - 27. Juni 2018)
DOI: 10.1109/pcs.2018.8456262
BibTeX: Download - , , , , :
A Hybrid Approach for Runtime Analysis Using a Cycle and Instruction Accurate Model
Architecture of Computing Systems (ARCS) (Braunschweig, 9. April 2018 - 12. April 2018)
In: Mladen Berekovic, Rainer Buchty, Heiko Hamann, Dirk Koch, Thilo Pionteck (Hrsg.): 31st International Conference on Architecture of Computing Systems (ARCS) 2018
DOI: 10.1007/978-3-319-77610-1_7
URL: http://arcs2018.itec.kit.edu/
BibTeX: Download
2017
- , :
Scalable Near-Lossless Video Compression Based on HEVC
IEEE Visual Communications and Image Processing (VCIP) (St. Petersburg, Florida, 10. Dezember 2017 - 13. Dezember 2017)
DOI: 10.1109/VCIP.2017.8305068
BibTeX: Download - , , , , , :
A Low-Complexity Metric for the Estimation of Perceived Chrominance Sub-Sampling Errors in Screen Content Images
IEEE Int. Conf. on Image Processing (ICIP) (Beijing, 17. September 2017 - 20. September 2017)
DOI: 10.1109/ICIP.2017.8296878
BibTeX: Download - , , :
Low-Complexity Enhancement Layer Compression for Scalable Lossless Video Coding based on HEVC
In: IEEE Transactions on Circuits and Systems For Video Technology 27 (2017), S. 1749 - 1760
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2016.2556338
URL: http://ieeexplore.ieee.org/document/7457283/
BibTeX: Download - , :
Video Decoding Energy Estimation Using Processor Events
IEEE International Conference on Image Processing (ICIP) (Beijing, 17. September 2017 - 20. September 2017)
DOI: 10.1109/ICIP.2017.8296731
BibTeX: Download - , :
Improving Mesh-Based Motion Compensation by Using Edge Adaptive Graph-Based Compensated Wavelet-Lifting for Medical Data Sets
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP) (New Orleans, LA, 5. März 2017 - 9. März 2017)
DOI: 10.1109/ICASSP.2017.7952408
BibTeX: Download
2016
- , , :
Fast CU Split Decisions for HEVC Inter Coding Using Support Vector Machines
Picture Coding Symposium (PCS) (Nuremberg, 4. Dezember 2016 - 7. Dezember 2016)
DOI: 10.1109/PCS.2016.7906358
BibTeX: Download - , :
Fast Exclusion of Angular Intra Prediction Modes in HEVC Using Reference Sample Variance
IEEE International Symposium on Circuits and Systems (ISCAS) (Montréal, 22. Mai 2016 - 25. Mai 2016)
DOI: 10.1109/ISCAS.2016.7539144
BibTeX: Download - , , :
Two-Stage Exclusion of Angular Intra Prediction Modes for Fast Mode Decision in HEVC
IEEE International Conference on Image Processing (ICIP) (Phoenix, AZ, 25. September 2016 - 28. September 2016)
DOI: 10.1109/ICIP.2016.7532413
BibTeX: Download - , :
Joint Optimization of Rate, Distortion, and Decoding Energy for HEVC Intraframe Coding
IEEE International Conference on Image Processing (ICIP) (Phoenix, Arizona, 25. September 2016 - 28. September 2016)
DOI: 10.1109/ICIP.2016.7532416
URL: http://arxiv.org/abs/2203.01765
BibTeX: Download - , , , , :
Multi-Objective Design Space Exploration for the Optimization of the HEVC Mode Decision Process
Picture Coding Symposium(PCS) (Nürnberg, 4. Dezember 2016 - 7. Dezember 2016)
In: Picture Coding Symposium (PCS) 2016
DOI: 10.1109/PCS.2016.7906327
URL: http://arxiv.org/abs/2203.01782
BibTeX: Download - , , , , :
A Bitstream Feature Based Model for Video Decoding Energy Estimation
Picture Coding Symposium (PCS) (Nürnberg, 4. Dezember 2016 - 7. Dezember 2016)
DOI: 10.1109/PCS.2016.7906400
URL: https://doi.org/10.48550/arXiv.2204.10151
BibTeX: Download - , :
Graph-Based Compensated Wavelet Lifting for 3-D+t Medical CT Data
Picture Coding Symposium (Nuremberg, 4. Dezember 2016 - 7. Dezember 2016)
DOI: 10.1109/PCS.2016.7906385
BibTeX: Download - , , , , :
Analysis and Exploitation of CTU-Level Parallelism in the HEVC Mode Decision Process Using Actor-based Modeling
Architecture of Computing Systems (ARCS) (Nürnberg, 4. April 2016 - 7. April 2016)
In: Springer (Hrsg.): In Proceedings of the International Conference on Architecture of Computing Systems (ARCS), Berlin; Heidelberg: 2016
DOI: 10.1007/978-3-319-30695-7_20
BibTeX: Download - , , , :
Probability Distribution Estimation for Autoregressive Pixel-Predictive Image Coding
In: IEEE Transactions on Image Processing 25 (2016), S. 1382-1395
ISSN: 1057-7149
DOI: 10.1109/TIP.2016.2522339
BibTeX: Download
2015
- , :
Fast intra mode decision in HEVC using early distortion estimation
IEEE China Summit and International Conference on Signal and Information Processing, ChinaSIP 2015 (Chengdu, 12. Juli 2015 - 15. Juli 2015)
DOI: 10.1109/ChinaSIP.2015.7230465
BibTeX: Download - , :
Estimating The HEVC Decoding Energy Using High-Level Video Features
European Signal Processing Conference (EUSIPCO) (Nice, 31. August 2015 - 4. September 2015)
In: Proc. of European Signal Processing Conference (EUSIPCO) 2015
DOI: 10.1109/EUSIPCO.2015.7362652
BibTeX: Download - , , , , , :
Estimation of Non-functional Properties for Embedded Hardware with Application to Image Processing
22nd Reconfigurable Architectures Workshop (RAW) on the 29th Annual International Parallel & Distributed Processing Symposium (IPDPS) (Hyderabad, 25. Mai 2015 - 29. Mai 2015)
DOI: 10.1109/IPDPSW.2015.58
URL: http://arxiv.org/abs/2203.01771
BibTeX: Download - , , :
Estimating the HEVC Decoding Energy Using the Decoder Processing Time
IEEE Int. Symp. on Circuits and Systems (ISCAS) (Lisbon, 24. Mai 2015 - 27. Mai 2015)
In: Proc. of IEEE Int. Symp. on Circuits and Systems (ISCAS) 2015
DOI: 10.1109/ISCAS.2015.7168683
URL: http://arxiv.org/abs/2203.01767
BibTeX: Download
2014
- , , , , :
Estimating Video Decoding Energies And Processing Times Utilizing Virtual Hardware
3PMCES Workshop. Design, Automation & Test in Europe (DATE) (Dresden, 24. März 2014 - 28. März 2014)
BibTeX: Download - , :
Coding of Distortion-Corrected Fisheye Video Sequences Using H.265/HEVC
IEEE International Conference on Image Processing (ICIP) (Paris, 27. Oktober 2014 - 30. Oktober 2014)
In: Proc. of IEEE International Conference on Image Processing (ICIP) 2014
DOI: 10.1109/ICIP.2014.7025839
BibTeX: Download - , , :
Sample-based Weighted Prediction for Lossless Enhancement Layer Coding in SHVC
IEEE International Conference on Image Processing (ICIP) (Paris, 27. Oktober 2014 - 30. Oktober 2014)
DOI: 10.1109/ICIP.2014.7025742
BibTeX: Download - , , :
Analysis of prediction algorithms for residual compression in a lossy to lossless scalable video coding system based on HEVC
Applications of Digital Image Processing XXXVII (San Diego, CA, 17. August 2014 - 21. August 2014)
DOI: 10.1117/12.2061597
BibTeX: Download - , , :
Modeling the Energy Consumption of HEVC P- and B-Frame Decoding
Intl. Conference on Image Processing (ICIP) (Paris, 27. Oktober 2014 - 30. Oktober 2014)
In: Proc. of Intl. Conf. on Image Processing (ICIP) 2014
DOI: 10.1109/ICIP.2014.7025743
BibTeX: Download - , , , , , :
Multiple description coding with randomly and uniformly offset quantizers
In: IEEE Transactions on Image Processing 23 (2014), S. 582-595
ISSN: 1057-7149
DOI: 10.1109/TIP.2013.2288928
BibTeX: Download - , , , , :
3-D mesh compensated wavelet lifting for 3-D+t medical CT data
IEEE International Conference on Image Processing (Paris, 27. Oktober 2014 - 30. Oktober 2014)
DOI: 10.1109/ICIP.2014.7025737
BibTeX: Download - , , , , :
Efficient lossless coding of highpass bands from block-based motion compensated wavelet lifting using JPEG 2000
IEEE Int. Conf. on Visual Communications and Image Processing (VCIP) (Valletta, 7. Dezember 2014 - 10. Dezember 2014)
DOI: 10.1109/VCIP.2014.7051590
BibTeX: Download - , , , , , :
Open source HEVC analyzer for rapid prototyping (HARP)
IEEE International Conference on Image Processing (Paris, 27. Oktober 2014 - 30. Oktober 2014)
DOI: 10.1109/ICIP.2014.7025443
BibTeX: Download - , , , , :
In-loop noise-filtered prediction for high efficiency video coding
In: IEEE Transactions on Circuits and Systems For Video Technology 24 (2014), S. 1142-1155
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2014.2302377
BibTeX: Download
2013
- , , :
Sample-based Weighted Prediction for Lossless Enhancement Layer Coding in HEVC
Grand Challenge at Picture Coding Symposium (PCS) (San José, CA, 8. Dezember 2013)
BibTeX: Download - , , , :
Modeling the energy consumption of HEVC intra decoding
2013 20th International Conference on Systems, Signals and Image Processing, IWSSIP 2013 (Bucharest, 7. Juli 2013 - 9. Juli 2013)
DOI: 10.1109/IWSSIP.2013.6623457
URL: http://arxiv.org/abs/2203.01755
BibTeX: Download - , , , , , :
Multiple description coding with randomly offset quantizers
2013 IEEE International Symposium on Circuits and Systems, ISCAS 2013 (Beijing, 19. Mai 2013 - 23. Mai 2013)
DOI: 10.1109/ISCAS.2013.6571832
BibTeX: Download - , , , , , :
M-channel multiple description coding based on uniformly offset quantizers with optimal deadzone
2013 38th IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2013 (Vancouver, BC, 26. Mai 2013 - 31. Mai 2013)
DOI: 10.1109/ICASSP.2013.6638009
BibTeX: Download - , , , , :
Spiral search based fast rotation estimation for efficient HEVC compression of navigation video sequences
2013 Picture Coding Symposium, PCS 2013 (San Jose, CA, 8. Dezember 2013 - 11. Dezember 2013)
DOI: 10.1109/PCS.2013.6737718
BibTeX: Download - , , , :
Motion vector analysis based homography estimation for efficient HEVC compression of 2D and 3D navigation video sequences
2013 20th IEEE International Conference on Image Processing, ICIP 2013 (Melbourne, VIC, 15. September 2013 - 18. September 2013)
DOI: 10.1109/ICIP.2013.6738359
BibTeX: Download - , , , :
Robust Rotational Motion Estimation for efficient HEVC compression of 2D and 3D navigation video sequences
2013 38th IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2013 (Vancouver, BC, 26. Mai 2013 - 31. Mai 2013)
DOI: 10.1109/ICASSP.2013.6637877
BibTeX: Download - , , , :
Near-lossless compression of computed tomography images using predictive coding with distortion optimization
SPIE Medical Imaging 2013: Image Processing (Lake Buena Vista, Florida, 9. Februar 2013 - 14. Februar 2013)
DOI: 10.1117/12.2006931
BibTeX: Download - , , , , :
Volumetric deformation compensation in CUDA for coding of dynamic cardiac images
2013 Picture Coding Symposium, PCS 2013 (San Jose, CA, 8. Dezember 2013 - 11. Dezember 2013)
DOI: 10.1109/PCS.2013.6737715
BibTeX: Download - , , , , :
Massively parallel lossless compression of medical images using least-squares prediction and arithmetic coding
2013 20th IEEE International Conference on Image Processing, ICIP 2013 (Melbourne, VIC, 15. September 2013 - 18. September 2013)
DOI: 10.1109/ICIP.2013.6738346
BibTeX: Download - , , :
Formangepasste diskrete Cosinus Transformation für die Prädiktionsverbesserung im HEVC
15. ITG-Fachtagung für Elektronische Medien (Dortmund, 26. Februar 2013 - 27. Februar 2013)
In: 15. ITG-Fachtagung für Elektronische Medien, Dortmund, Deutschland: 2013
DOI: 10.17877/DE290R-14782
BibTeX: Download - , , , , :
Pixel-based averaging predictor for HEVC lossless coding
2013 20th IEEE International Conference on Image Processing, ICIP 2013 (Melbourne, VIC, 15. September 2013 - 18. September 2013)
DOI: 10.1109/ICIP.2013.6738372
BibTeX: Download - , , , , :
Sample-based weighted prediction with directional template matching for HEVC lossless coding
2013 Picture Coding Symposium, PCS 2013 (San Jose, CA, 8. Dezember 2013 - 11. Dezember 2013)
DOI: 10.1109/PCS.2013.6737744
BibTeX: Download
2012
- , , , :
Optimizing frame structure with real-time computation for interactive multiview video streaming
2012 3DTV-Conference: The True Vision - Capture, Transmission and Display of 3D Video, 3DTV-CON 2012 (Zürich, 15. Oktober 2012 - 17. Oktober 2012)
DOI: 10.1109/3DTV.2012.6365460
BibTeX: Download - , , , :
Analysis of Mesh-Based Motion Compensation in Wavelet Lifting of Dynamical 3-D+t CT Data
IEEE International Workshop on Multimedia Signal Processing (Banff, 17. September 2012 - 19. September 2012)
DOI: 10.1109/MMSP.2012.6343432
BibTeX: Download - , , , :
On the influence of clipping in lossless predictive and wavelet coding of noisy images
29th Picture Coding Symposium, PCS 2012 (Krakow, 7. Mai 2012 - 9. Mai 2012)
DOI: 10.1109/PCS.2012.6213323
BibTeX: Download - , , , :
Analysis of displacement compensation methods for wavelet lifting of medical 3-D thorax CT volume data
2012 IEEE Visual Communications and Image Processing, VCIP 2012 (San Diego, CA, 27. November 2012 - 30. November 2012)
DOI: 10.1109/VCIP.2012.6410751
BibTeX: Download - , , , :
Compression of 2D Navigation Views with Rotational and Translational Motion
Visual Information Processing and Communication III (San Francisco, CA, 22. Januar 2012)
DOI: 10.1117/12.911990
BibTeX: Download - , , , :
Compression of 2D and 3D navigation video sequences using skip mode masking of static areas
29th Picture Coding Symposium, PCS 2012 (Krakow, 7. Mai 2012 - 9. Mai 2012)
DOI: 10.1109/PCS.2012.6213352
BibTeX: Download - , , , :
Representation of deformable motion for compression of dynamic cardiac image data
Medical Imaging 2012: Image Processing (San Diego, CA, 4. Februar 2012 - 9. Februar 2012)
In: Proceedings of SPIE - The International Society for Optical Engineering 8314 2012
DOI: 10.1117/12.911276
BibTeX: Download - , , , :
Mode adaptive reference frame denoising for high fidelity compression in HEVC
2012 IEEE Visual Communications and Image Processing, VCIP 2012 (San Diego, CA, 27. November 2012 - 30. November 2012)
DOI: 10.1109/VCIP.2012.6410777
BibTeX: Download
2011
- , , :
Methods and tools for wavelet-based scalable multiview video coding
In: IEEE Transactions on Circuits and Systems For Video Technology 21 (2011), S. 113-126
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2011.2105552
BibTeX: Download - , , , :
Analysis of Inter-Layer Prediction and Hierarchical Prediction Structures in Scalable Video Coding
In: IEEE Transactions on Broadcasting 57 (2011), S. 66-74
ISSN: 0018-9316
DOI: 10.1109/TBC.2010.2082370
BibTeX: Download - , :
Reusing the H.264/AVC deblocking filter for efficient spatio-temporal prediction in video coding
36th IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2011 (Prague, 22. Mai 2011 - 27. Mai 2011)
DOI: 10.1109/ICASSP.2011.5946587
URL: https://arxiv.org/pdf/2207.01210.pdf
BibTeX: Download - , , , :
Sparse representation of dense motion vector fields for lossless compression of 4-D medical CT data
19th European Signal Processing Conference, EUSIPCO 2011 (Barcelona, 30. August 2011 - 2. September 2011)
DOI: 10.5281/zenodo.42439
BibTeX: Download - , , , , :
Adaptive in-loop noise-filtered prediction for high efficiency video coding
3rd IEEE International Workshop on Multimedia Signal Processing, MMSP 2011 (Hangzhou, 17. Oktober 2011 - 19. Oktober 2011)
DOI: 10.1109/MMSP.2011.6093773
BibTeX: Download - , , , , :
Efficient coding of video sequences by non-local in-loop denoising of reference frames
2011 18th IEEE International Conference on Image Processing, ICIP 2011 (Brussels, 11. September 2011 - 14. September 2011)
DOI: 10.1109/ICIP.2011.6115648
BibTeX: Download
2010
- , , , :
Adaptive quantization parameter cascading for hierarchical video coding
2010 IEEE International Symposium on Circuits and Systems: Nano-Bio Circuit Fabrics and Systems, ISCAS 2010 (Paris, 30. Mai 2010 - 2. Juni 2010)
DOI: 10.1109/ISCAS.2010.5537584
BibTeX: Download - , :
Multiple selection approximation for improved spatio-temporal prediction in video coding
2010 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2010 (Dallas, TX, 14. März 2010 - 19. März 2010)
DOI: 10.1109/ICASSP.2010.5495253
URL: https://arxiv.org/abs/2207.01207
BibTeX: Download - , , :
Spatio-temporal prediction in video coding by non-local means refined motion compensation
28th Picture Coding Symposium, PCS 2010 (Nagoya, 8. Dezember 2010 - 10. Dezember 2010)
DOI: 10.1109/PCS.2010.5702497
URL: https://arxiv.org/abs/2207.09729
BibTeX: Download - , , , :
In-loop denoising of reference frames for lossless coding of noisy image sequences
2010 17th IEEE International Conference on Image Processing, ICIP 2010 (Hong Kong, 26. September 2010 - 29. September 2010)
DOI: 10.1109/ICIP.2010.5654136
BibTeX: Download - , , , , :
Analysis of in-loop denoising in lossy transform coding
28th Picture Coding Symposium, PCS 2010 (Nagoya, 8. Dezember 2010 - 10. Dezember 2010)
DOI: 10.1109/PCS.2010.5702584
BibTeX: Download
2009
- , :
Analysis on Spatial Scalable Multiview Video Coding with Wavelets
2009 IEEE International Workshop on Multimedia Signal Processing, MMSP '09 (Rio De Janeiro, 5. Oktober 2009 - 7. Oktober 2009)
DOI: 10.1109/MMSP.2009.5293340
BibTeX: Download - , , :
Optimized Anisotropic Spatial Transforms for Wavelet-Based Scalable Multi-View Video Coding
Visual Communications and Image Processing 2009 (San Jose, CA, 18. Januar 2009 - 22. Januar 2009)
DOI: 10.1117/12.807250
BibTeX: Download - , , , :
Lagrange multiplier selection for rate-distortion optimization in SVC
2009 Picture Coding Symposium, PCS 2009 (Chicago, IL, 6. Mai 2009 - 8. Mai 2009)
DOI: 10.1109/PCS.2009.5167399
BibTeX: Download - , , , :
Model based analysis for quantization parameter cascading in hierarchical video coding
2009 IEEE International Conference on Image Processing, ICIP 2009 (Cairo, 7. November 2009 - 10. November 2009)
DOI: 10.1109/ICIP.2009.5414354
BibTeX: Download - , , , :
One-Pass Multi-Layer Rate-Distortion Optimization for H.264/SVC Quality Scalable Video Coding
2009 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2009 (Taipei, 19. April 2009 - 24. April 2009)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=70349459711∨igin=inward
BibTeX: Download - , , :
One-Pass Frame Level Budget Allocation Based on inter-frame Dependency
2009 IEEE International Workshop on Multimedia Signal Processing, MMSP '09 (Rio De Janeiro, 5. Oktober 2009 - 7. Oktober 2009)
DOI: 10.1109/MMSP.2009.5293245
BibTeX: Download - , , :
Efficient one-pass frame level rate control for H.264/AVC
In: Journal of Visual Communication and Image Representation 20 (2009), S. 585-594
ISSN: 1047-3203
DOI: 10.1016/j.jvcir.2009.09.001
BibTeX: Download - , , , :
Laplace distribution based Lagrangian rate distortion optimization for hybrid video coding
In: IEEE Transactions on Circuits and Systems For Video Technology 19 (2009), S. 193-205
ISSN: 1051-8215
DOI: 10.1109/TCSVT.2008.2009255
BibTeX: Download - , , :
Spatio-temporal prediction in video coding by best approximation
2009 Picture Coding Symposium, PCS 2009 (Chicago, IL, 6. Mai 2009 - 8. Mai 2009)
DOI: 10.1109/PCS.2009.5167407
URL: https://arxiv.org/abs/2207.09727
BibTeX: Download - , :
Lossy compression of floating point High Dynamic Range images using JPEG2000
Visual Communications and Image Processing 2009 (San Jose, CA, 18. Januar 2009 - 22. Januar 2009)
DOI: 10.1117/12.805315
BibTeX: Download
2008
- , , , :
Wavelet-based multi-view video coding with joint best basis wavelet packets
2008 IEEE International Conference on Image Processing, ICIP 2008 (San Diego, CA, 12. Oktober 2008 - 15. Oktober 2008)
DOI: 10.1109/ICIP.2008.4711984
BibTeX: Download - , , , :
On the Efficiency of Inter-Layer Prediction in H.264/AVC Quality Scalable Video Coding
IEEE International Symposium on Recent Advances in Communication Engineering (, 20. Dezember 2008 - 23. Dezember 2008)
BibTeX: Download - , , , :
Rate-distortion optimized frame level rate control for H.264/AVC
16th European Signal Processing Conference, EUSIPCO 2008 (Lausanne, 25. August 2008 - 29. August 2008)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84863745721∨igin=inward
BibTeX: Download - , :
Analysis of Compression of 4D Volumetric Medical Image Datasets Using Multi-View Video Coding Methods
Mathematics of Data/Image Pattern Recognition, Compression, and Encryption with Applications XI (San Diego, CA, 10. August 2008 - 14. August 2008)
DOI: 10.1117/12.794483
BibTeX: Download - , :
Analysis of spatio-temporal prediction methods in 4D volumetric medical image datasets
2008 IEEE International Conference on Multimedia and Expo, ICME 2008 (Hannover, 23. Juni 2008 - 26. Juni 2008)
DOI: 10.1109/ICME.2008.4607487
BibTeX: Download - , :
Spatial scalable JPEG2000 transcoding and tracking of regions of interest for video surveillance
13th International Fall Workshop Vision, Modeling, and Visualization 2008, VMV 2008 (Konstanz, 8. Oktober 2008 - 10. Oktober 2009)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84881575723∨igin=inward
BibTeX: Download - , :
Spatio-temporal prediction in video coding by spatially refined motion compensation
2008 IEEE International Conference on Image Processing, ICIP 2008 (San Diego, CA, 12. Oktober 2008 - 15. Oktober 2008)
DOI: 10.1109/ICIP.2008.4712373
URL: https://arxiv.org/abs/2207.03766
BibTeX: Download
2007
- , , :
Fast Video Transcoding from H.263 To H. 264/AVC
In: Multimedia Tools and Applications 35 (2007), S. 127-146
ISSN: 1380-7501
DOI: 10.1007/s11042-007-0126-7
BibTeX: Download - , :
Complexity evaluation of random access to coded multi-view video data
15th European Signal Processing Conference, EUSIPCO 2007 (Poznan, 3. September 2007 - 7. September 2007)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=80051659180∨igin=inward
BibTeX: Download - , , , , , :
H.263 to H.264 transconding using data mining
14th IEEE International Conference on Image Processing, ICIP 2007 (San Antonio, Texas, 16. September 2007 - 19. September 2007)
DOI: 10.1109/ICIP.2007.4379959
BibTeX: Download - , , :
Wavelet-based multi-view video coding with full scalability and illumination compensation
15th ACM International Conference on Multimedia, MM'07 (Augsburg, Bavaria, 24. September 2007 - 29. September 2007)
DOI: 10.1145/1291233.1291402
BibTeX: Download - , :
Inter-scale prediction of motion information for a wavelet-based scalable video coder
26th Picture Coding Symposium, PCS 2007 (Lisbon, 7. November 2007 - 9. November 2007)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84898062563∨igin=inward
BibTeX: Download - , :
Wavelet-based multi-view video coding with spatial scalability
2007 IEEE 9Th International Workshop on Multimedia Signal Processing, MMSP 2007 (Chania, Crete, 1. Oktober 2007 - 3. Oktober 2007)
DOI: 10.1109/MMSP.2007.4412906
BibTeX: Download - , , , :
Advanced Lagrange multiplier selection for hybrid video coding
IEEE International Conference onMultimedia and Expo, ICME 2007 (Beijing, 2. Juli 2007 - 5. Juli 2007)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=46449128611∨igin=inward
BibTeX: Download - , , :
Adaptive lagrange multiplier selection for intra-frame video coding
2007 IEEE International Symposium on Circuits and Systems, ISCAS 2007 (New Orleans, LA, 27. Mai 2007 - 30. Mai 2007)
DOI: 10.1109/ISCAS.2007.378542
BibTeX: Download - , , , :
Extended lagrange multiplier selection for hybrid video coding using interframe correlation
26th Picture Coding Symposium, PCS 2007 (Lisbon, 7. November 2007 - 9. November 2007)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84898070973∨igin=inward
BibTeX: Download
2006
- , , :
Overview of low-complexity video transcoding from H.263 to H.264
2006 IEEE International Conference on Multimedia and Expo, ICME 2006 (Toronto, ON, 9. Oktober 2006 - 12. Oktober 2006)
DOI: 10.1109/ICME.2006.262547
BibTeX: Download - , , :
A new algorithm for reducing the requantization loss in video transcoding
14th European Signal Processing Conference, EUSIPCO 2006 (Florence, 4. September 2006 - 8. September 2006)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84862633686∨igin=inward
BibTeX: Download - , , , :
Low-complexity transcoding of inter coded video frames from H.264 to H.263
2006 IEEE International Conference on Image Processing, ICIP 2006 (Atlanta, GA, 8. Oktober 2006 - 11. Oktober 2006)
DOI: 10.1109/ICIP.2006.312532
BibTeX: Download - , , :
Improving the prediction efficiency for multi-view video coding using histogram matching
25th PCS: Picture Coding Symposium 2006, PCS2006 (Beijing, 24. April 2006 - 26. April 2006)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=34047168689∨igin=inward
BibTeX: Download - , , , :
Depth map compression for unstructured lumigraph rendering
Visual Communications and Image Processing (VCIP 2006) (San Jose, CA, 15. Januar 2006 - 19. Januar 2006)
DOI: 10.1117/12.642803
BibTeX: Download - , , , :
4D scalable multi-view video coding using disparity compensated view filtering and motion compensated temporal filtering
2006 IEEE 8th Workshop on Multimedia Signal Processing, MMSP 2006 (Victoria, BC, 3. Oktober 2006 - 6. Oktober 2006)
DOI: 10.1109/MMSP.2006.285268
BibTeX: Download - , :
Analysis of Multi-Reference Block Matching for Multi-View Video Coding
7th Workshop Digital Broadcasting (Erlangen, 14. September 2006 - 15. September 2006)
BibTeX: Download - , , , :
BeTrIS - An Index System for MPEG-7 Streams
In: EURASIP J APPL SIG P 2006 (2006), S. 1-11
ISSN: 1110-8657
DOI: 10.1155/ASP/2006/15482
BibTeX: Download - , , :
Gradient intra prediction for coding of computer animated video
2006 IEEE 8th Workshop on Multimedia Signal Processing, MMSP 2006 (Victoria, BC, 3. Oktober 2006 - 6. Oktober 2006)
DOI: 10.1109/MMSP.2006.285267
BibTeX: Download
2005
- , , :
On requantization in intra-frame video transcoding with different transform block sizes
2005 IEEE 7th Workshop on Multimedia Signal Processing, MMSP 2005 (Shanghai, 30. Oktober 2005 - 2. November 2005)
DOI: 10.1109/MMSP.2005.248669
BibTeX: Download - , :
H.264/AVC-compatible coding of dynamic light fields using transposed picture ordering
13th European Signal Processing Conference, EUSIPCO 2005 (Antalya, 4. September 2005 - 8. September 2005)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=34247167330∨igin=inward
BibTeX: Download - , :
Statistical Analysis of Multi-Reference Block Matching for Dynamic Light Field Coding
10th International Fall Workshop - Vision, Modeling, and Visualization (VMV) (Erlangen, 16. November 2005 - 18. November 2005)
BibTeX: Download
2004
- , , :
Fast transcoding of intra frames between H.263 and H.264
2004 International Conference on Image Processing, ICIP 2004 (Singapore, 24. Oktober 2004 - 27. Oktober 2004)
DOI: 10.1109/ICIP.2004.1421682
BibTeX: Download - , , , :
A fast H.263 to H.264 inter-frame transcoder with motion vector refinement
Picture Coding Symposium 2004 (San Francisco, CA, 15. Dezember 2004 - 17. Dezember 2004)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=18144406177&origin=inward
BibTeX: Download - , , :
Error control and concealment of JPEG2000 coded image data in error prone environments
Picture Coding Symposium 2004 (San Francisco, CA, 15. Dezember 2004 - 17. Dezember 2004)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=18144396226&origin=inward
BibTeX: Download - , , :
Serially Connected Channels: Capacity and Video Streaming Application Scenario for Separate and Joint Channel Coding
5th International ITG Conference on Source and Channel Coding (SCC) (Erlangen, 14. Januar 2004 - 16. Januar 2004)
URL: https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=1642574168&origin=inward
BibTeX: Download
2002
- , , :
Multimedia Messaging mit MPEG-7
In: Fachzeitschrift für Fernsehen, Film und elektronische Medien 56 (2002), S. 27-30
ISSN: 1430-9947
BibTeX: Download - , , , , :
An MPEG-7 tool for compression and streaming of XML data
2002 IEEE International Conference on Multimedia and Expo, ICME 2002 (, 25. August 2002 - 29. August 2002)
DOI: 10.1109/ICME.2002.1035833
BibTeX: Download
2001
- , , :
Multimedia Messaging Technologien auf der Basis von MPEG-7
In: ITG-Fachbericht (2001), S. 157-162
ISSN: 0932-6022
BibTeX: Download - , , :
Adaptive Multimedia Messaging: Application Scenario and Technical Challenges
Wireless World Research Forum (Munich, 6. März 2001 - 7. März 2001)
BibTeX: Download - :
MPEG-Standards: Techniken und Entwicklungstrends
In: Fachzeitschrift für Fernsehen, Film und elektronische Medien 55 (2001), S. 352-362
ISSN: 1430-9947
BibTeX: Download
2000
- , :
A Simple Multiple Video Objects Rate Control Algorithm for MPEG-4 Real-Time Applications
3. ITG Conference on Source and Channel Coding, ITG-Fachbericht 159 (Munich, 17. Januar 2000 - 19. Januar 2000)
BibTeX: Download
1999
- :
Object-Based Texture Coding of Moving Video in MPEG-4
In: IEEE Transactions on Circuits and Systems For Video Technology 9 (1999), S. 5-15
ISSN: 1051-8215
BibTeX: Download - , :
Performance and Complexity Analysis of Rate Constrained Motion Estimation in MPEG-4
In: Proceedings Multimedia Systems and Applications II, SPIE 1999
BibTeX: Download - , :
Leistungsfähigkeit und Komplexität von ratengesteuerter Bewegungsschätzung in MPEG-4
Multimedia: Anwendungen, Technologie, Systeme, ITG-Fachbericht 156 (, 27. September 1999 - 29. September 1999)
BibTeX: Download
1998
- , , , , :
Der MPEG-4 Multimedia-Standard und seine Anwendungen im MINT-Projekt
In: Der Fernmelde-Ingenieur 52 (1998), S. 43-64
ISSN: 0015-010X
BibTeX: Download - , , , :
Mobile Multimediakommunikation über DECT, ISDN und LAN
In: Der Fernmelde-Ingenieur 52 (1998), S. 65-74
ISSN: 0015-010X
BibTeX: Download - :
Reduction of Ringing Noise in Transform Image Coding Using a Simple Adaptive Filter
In: Electronics Letters 34 (1998), S. 2110-2112
ISSN: 0013-5194
BibTeX: Download - , :
Objektbasierte Codierung von bewegungskompensierten Prädiktionsfehlerbildern in MPEG-4
2. ITG-Fachtagung Codierung für Quelle, Kanal und Übertragung, ITG-Fachbericht 146 (Aachen, 3. März 1998 - 5. März 1998)
BibTeX: Download - , , , , , , , :
Complexity and PSNR-Comparison of Several Fast Motion Estimation Algorithms for MPEG-4
Applications of Digital Image Processing XXI, SPIE (San Diego, 21. Juli 1998 - 24. Juli 1998)
BibTeX: Download - , , , , , :
MPEG-4 for Broadband Communications
Multimedia Systems and Applications, SPIE (Boston, Mass., 2. November 1998 - 4. November 1998)
BibTeX: Download
1997
- , , , :
Mobile Multimediakommunikation über DECT, ISDN und LAN
Multimedia: Anwendungen, Technologie, Systeme, ITG-Fachbericht 144 (Dortmund, 29. September 1997 - 1. Oktober 1997)
BibTeX: Download - :
Adaptive constrained least squares restoration for removal of blocking artifacts in low bit rate video coding
IEEE International Conference on Acoustics, Speech, and Signal Processing (Munich, 21. April 1997 - 24. April 1997)
BibTeX: Download - :
Adaptive Low-Pass Extrapolation for Object-Based Texture Coding of Moving Video
Visual Communications and Image Processing, SPIE (San José, 12. Februar 1997 - 14. Februar 1997)
BibTeX: Download - , :
On the Performance of the Shape Adaptive DCT in Object-Based Coding of Motion Compensated Difference Images
Picture Coding Symposium, ITG-Fachbericht 143 (Berlin, 10. September 1997 - 12. September 1997)
BibTeX: Download - , , :
Reduction of Block Artifacts by Selective Removal and Reconstruction of the Block Borders
Picture Coding Symposium, ITG-Fachbericht 143 (Berlin, 10. September 1997 - 12. September 1997)
BibTeX: Download
1996
- , , :
Improving the Image Quality of Blockbased Video Coders by Exploiting Interblock Redundancy
First International Workshop on Wireless Image/Video Communications, Loughborough (, 4. September 1996 - 5. September 2010)
BibTeX: Download - , , :
Quality Improvement of Low Data-rate Compressed Video Signals by Pre- and Postprocessing
Digital Compression Technologies and Systems for Video Communications, Berlin (, 7. Oktober 1996 - 9. Oktober 1996)
BibTeX: Download
1994
- , :
Efficient Prediction of Uncovered Background in Interframe Coding Using Spatial Extrapolation
IEEE International Conference on Acoustics, Speech, and Signal Processing, Adelainde (, 19. April 1994 - 22. April 1994)
BibTeX: Download - , :
Uncovered Background Prediction in an Object-Oriented Coding Environment
International Workshop on Coding Techniques for Very Low Bit-rate Video, Colchester (, 7. April 1994 - 8. April 1994)
BibTeX: Download
1993
- , :
Region-Based Image Coding Using Functional Approximation
Picture Coding Symposium, Lausanne (, 17. März 1993 - 19. März 1993)
BibTeX: Download
1991
- , :
DSP-Based Compression of Four-Color Printed Images
International Conference on DSP Applications and Technology, Berlin (, 28. Oktober 1991 - 31. Oktober 1991)
BibTeX: Download - , :
Variable Blocksize Transform Coding of Four-Color Printed Images
Visual Communication and Image Processing, Boston, Mass., SPIE (, 11. November 1991 - 13. November 1991)
BibTeX: Download