Videokommunikation
Unser Lehrstuhl beschäftigt sich mit einer Vielzahl an Themen rund um die Videokompression. Dabei erforschen wir aktuelle Videocodierstandards wie HEVC und entwickeln neue Kompressionsmethoden für zukünftige Codecs wie VVC. Zusätzlich betrachten wir völlig neue Codieransätze für spezielle Inhalte wie Medizindatensätze, computergenerierte Videos, Fisheye- und 360°-Videodaten.
Codierung mit Hilfe des Machine Learning
Videocodierung für maschinelle Kommunikation basierend auf tiefem Lernen
| Ihr Ansprechpartner |
| Marc Windsheimer, M.Sc. |
| E-Mail: marc.windsheimer@fau.de |
| Link zur Person |
Üblicherweise sind aktuelle Videocodecs auf das menschliche Wahrnehmungsvermögen ausgelegt und optimiert. Allerdings gewinnt die sogenannte Maschine-zu-Maschine (M2M) Kommunikation immer mehr an Bedeutung, bei denen maschinelle Algorithmen das resultierende komprimierte Videosignal analysieren, um damit bestimmte Aufgaben erfüllen zu können. Diese Aufgaben erstrecken sich von der Automatisierung industrieller Prozesse, der Überwachung von öffentlichen Orten bis hin zum autonomen Fahren von Autos. Bei solchen Szenarien ist dann nicht mehr die subjektive visuelle Qualität für den Menschen maßgeblich, sondern die Detektionsrate des Algorithmus. Bei den Algorithmen, die final die Qualität der Codierung bewerten, wird der Fokus auf neuronale Objektdetektionnetzwerke (R-CNNs) gelegt
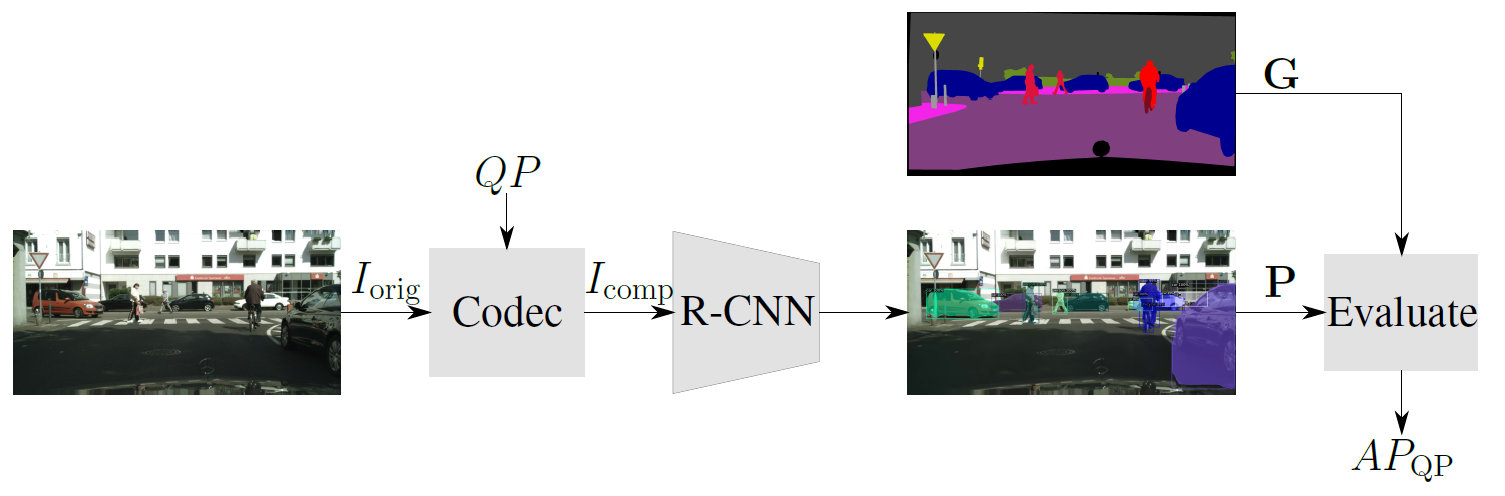
Die entscheidende Frage für die Videokompression in der M2M-Kommunikation ist nun, wie stark die Originaldaten komprimiert werden können, um immer noch ein zufriedenstellendes Dektionsergebnis zu bekommen. Außerdem kann hier die Frage gestellt werden, ob andere Ansätze für den Videocodec verwendet werden sollten, um ein möglichst optimales Verhältnis aus Kompressions- und Detektionsrate zu erlangen.
Deep Learning für Videocodierung
Conditional Inter Frame Coding
| Ihr Ansprechpartner |
| Fabian Brand, M.Sc. |
| E-Mail: fabian.brand@fau.de |
| Link zur Person. |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link zur Person. |
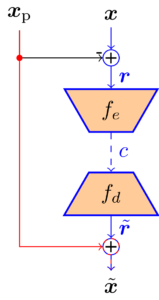
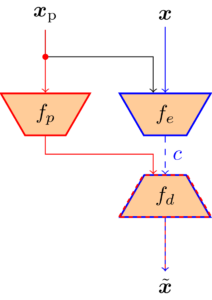
Der Einsatz neuraler Netze macht die Videokompression deutlich flexibler, da zugrundeliegende Statistiken und Wahrscheinlichkeitsfunktionen direkt aus den Daten gelernt werden können, während traditionelle Videocoder auf händisch designten Transformationen und Statistiken beruhen. Gegenstand dieses Forschungsbereiches ist die Anwendung von sogenanntem Conditional Inter Frame Coding. Dieser Ansatz löst das Problem der prädizierten Übertragung eines Frames in einem Video. Um zeitliche Redundanz auszunutzen liegt ein Prädiktionssignal, welches aus dem vorherigen Frame generiert wird vor. Traditionell wird dieses Prädiktionssignal von dem aktuellen Frame subtrahiert und das Differenzbild wird übertragen bevor es auf der Decoderseite wieder auf das Prädiktionssignal addiert wird. Mithilfe der Informationstheorie lässt sich jedoch zeigen, dass dieser Weg nicht optimal ist. Es ist wesentlich besser, den aktuellen Frame unter der Bedingung, dass das Prädiktionssignal bekannt ist zu übertragen. Einen solchen conditional Coder umzusetzen ist mit traditionellen Methoden jedoch nur sehr schwer möglich. Neuronale Netze hingegen können die entsprechende Statistik jedoch direkt lernen.
In diesem Bereich erforschen wir die theoretischen und praktischen Eigenschaften einen Conditional Inter Frame Coders. Fokus liegt hier auf der Beschreibung, Modellierung und Behebung von sogenannten Information Bottlenecks, die bei conditional Codern auftreten und die Leistung schmälern können.
|
Residual Coder
|
Conditional Coder
|
End-to-End optimierte Bild- und Videocodierung
| Ihr Ansprechpartner |
| Anna Meyer, M.Sc. |
| E-Mail: anna.meyer@fau.de |
| Link zur Person |
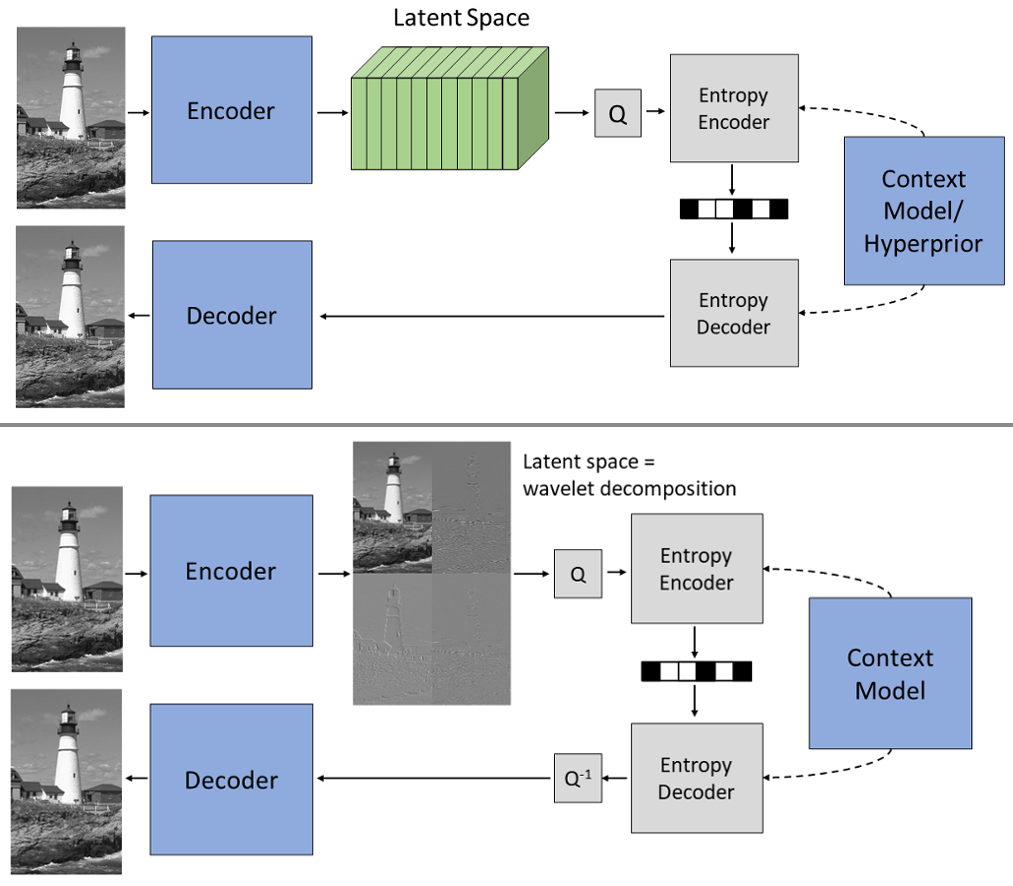
In letzter Zeit wurden verschiedene Komponenten von Videocodern erfolgreich mit neuronalen Netzen verbessert. Diese Ansätze beruhen jedoch auf separat entwickelten und optimierten Modulen. End-to-End-optimierte Bild- und Videocodierung ist ein aktuelles Forschungsgebiet, das eine gemeinsame Optimierung des gesamten Codierungssystems ermöglicht. Die beliebtesten Ansätze basieren dabei auf komprimierenden Autoencodern: Der Encoder berechnet eine sogenannte Latent Space Repräsentation, die anschließend quantisiert und mittels Entropiecodierung verlustfrei komprimiert wird. Anschließend berechnet der Decoder das rekonstruierte Bild oder Video ausgehend vom quantisiertem Latent Space.
Dabei hat sich gezeigt, dass der Latent Space redundante Informationen enthält, die z. B. durch ein örtliches Kontextmodell oder sogenanntes Channel Conditioning reduziert werden können. Mögliche weitere Redundanz auszunutzen ist wegen der fehlenden Interpretierbarkeit des Latent Space jedoch eine Herausforderung.
Ein interessanter Ansatz ist deswegen, Encoder und Decoder nach dem Lifting Schema aufzubauen. Dadurch erzeugt der Encoder einen Latent Space, der eine gelernte Wavelet-Zerlegung darstellt. Dieses Wissen über die Struktur des Latent Space erleichtert die Entwicklung effizienter lernbasierter Verfahren für die Bild- und Videokompression. Außerdem können Ansätze aus der klassischen Wavelet-Kompression übernommen werden.
Energieeffiziente Videokommunikation
Heutzutage wird die Videokommunikation weltweit von Milliarden von Nutzern verwendet. Die zugehörigen Applikationen werden auf verschiedensten Geräten durchgeführt, zum Beispiel Handys, Notebooks oder Fernseher. Eine aktuelle Studie hat in diesem Zusammenhang gezeigt, dass 1% der Treibhausgasemissionen durch Videokommunikationsanwendungen verursacht wird (Link). Hierin enthalten sind alle Faktoren wie die Aufnahme, die Speicherung, die Kompression, die Decodierung und die Übertragung der Videodaten. Aufgrund dieses hohen Anteils und dem prognostizierten Wachstum ist es sehr wichtig, den tatsächlichen Energieverbrauch aller dieser Systeme zu erforschen, um für die Zukunft neue, energieeffiziente Lösungen entwickeln zu können.
![]()
Daher beschäftigen wir uns in diesem Forschungsthema mit der energieffizienten Videokommunikation. Dazu haben wir in den letzten Jahren verschiedenste Messaufbauten entwickelt, um Hardwaremodule wie Handys, Evaluationsboards, einzelne Chips oder PCs energetisch zu vermessen. Mit Hilfe dieser Daten entwickeln wir extrem genaue Energie- und Leistungsmodelle, die den Verbrauch während der Ausführung akkurat und verlässlich schätzen. Die Modelle werden schließlich dafür eingesetzt, neuartige und energieeffiziente Methoden vorzuschlagen und zu entwickeln.
Für die Zukunft wollen noch tiefer in die Thematik einsteigen und alle Komponenten im Detail betrachten, die in der Videokommunikation verwendet werden. Aktuell arbeiten wir an Themen wie die Übertragung der Videos, 360°-Videos, die Codierung und neue Videocodecs. Wir suchen stets nach neuen Themen und sind offen für interessante Abschlussarbeiten, Kollaborationen oder anderen Ideen.
Energieeffiziente Videocodierung
| Ihr Ansprechpartner |
| Matthias Kränzler, M.Sc. |
| E-Mail: matthias.kraenzler@fau.de |
| Link zur Person |
In den letzten Jahren steigen die Menge und der Anteil an Videodaten im globalen Internetdatenverkehr stetig an. Sowohl die Encodierung auf der Senderseite, als auch die Decodierung auf der Empfängerseite benötigen viel Energie. Forschung zu energieeffizienter Videodecodierung hat gezeigt, dass es möglich ist den Energiebedarf der Decodierung zu optimieren. Dieses Arbeitsgebiet beschäftigt sich mit der Modellierung der Energie, die für die Encodierung von komprimierten Videodaten notwendig ist. Ziel der Modellierung ist die Optimierung der Energieeffizienz der gesamten Videocodierung.

„Big Buck Bunny“ by Big Buck Bunny is licensed under CC BY 3.0
Energieeffiziente Videodekommunikation
| Ihr Ansprechpartner |
| Dr.-Ing. Christian Herglotz |
| E-Mail: christian.herglotz@fau.de |
| Link zur Person |
Dieses Arbeitsgebiet beschäftigt sich mit der energieeffizienten Decodierung von komprimierten Videodaten. Die Decodierung ist insbesondere für batteriebetriebene Geräte wie Smartphones oder Tablet PCs von Bedeutung, die z.B. bei mobilen Videostreaminganwendungen viel Energie benötigen.
Durch ausgeklügelte Algorithmen und Methoden kann dieser Energieverbrauch gesenkt werden, ohne dass die visuelle Qualität der Sequenzen leidet. Hierzu wurde in unserer Arbeit zuerst ein Modell erstellt, mit dem der Energieverbrauch eines Decoders anhand von Bitstrommerkmalen akkurat geschätzt werden kann. Die Energie lässt sich dann den Bitstrommerkmalen zuordnen und visualisieren.
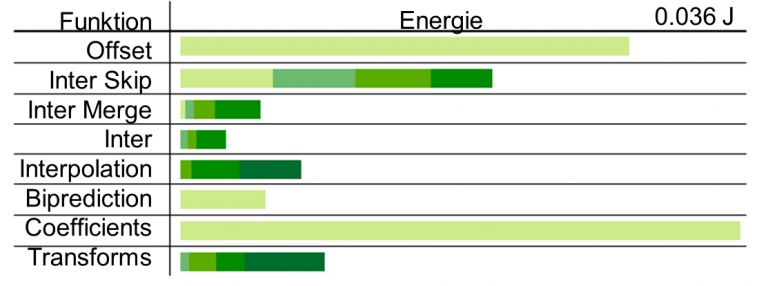

Ein entsprechender Coder, der dieses Modell ausnutzt, um energieeffiziente Bitströme zu generieren, kann auf folgender Seite heruntergeladen werden:
Decoding-Energy-Rate-Distortion Optimization (DERDO) for Video Coding
Codierung von Ultraweitwinkel- und 360°-Videodaten
Projektionsbasierte Videocodierung
| Ihr Ansprechpartner |
| Andy Regensky, M.Sc. |
| E-Mail: andy.regensky@fau.de |
| Link zur Person |
Ultraweitwinkel- und 360°-Videodaten unterliegen einer Vielzahl von Verzerrungen, welche bei herkömmlichen Videomaterial, das mit perspektivischen Objektiven aufgenommen wurde, nicht vorkommen. Diese Verzerrungen entstehen vor allem, da Ultraweitwinkelobjektive nicht dem Lochkameramodell folgen und somit spezielle Bildcharakteristiken vorliegen. Deutlich wird dies zum Beispiel dadurch, dass gerade Linien auf dem Bildsensor gebogen abgebildet werden. Nur so, sind Sichtfelder von 180° und mehr mit nur einer Kamera realisierbar. Mittels sogenannter Stitching-Verfahren können mehrere Kameraansichten zu 360°-Aufnahmen kombiniert werden, die eine komplette Rundumsicht ermöglichen. Häufig wird dies durch den Einsatz von zwei Ultraweitwinkelkameras realisiert, wobei jede Kamera eine Halbkugel aufnimmt. Um die entstehenden sphärischen 360°-Aufnahmen mit Hilfe bestehender Videocodecs komprimieren zu können, müssen die Aufnahmen auf die zweidimensionale Bildfläche projiziert werden. Hierbei kommen verschiedene Abbildungsfunktionen zum Einsatz. Häufig fällt die Wahl auf das Equirectangular-Format, welches vergleichbar mit der Darstellung des Globus auf einer Weltkarte ist, und somit 360° in horizontaler, sowie 180° in vertikaler Richtung abbildet.
Da herkömmliche Videocodecs nicht auf die von der perspektivischen Projektion abweichenden Abbildungsformate abgestimmt sind, kommt es zu Verlusten, die durch eine Berücksichtigung der vorliegenden Projektionsformate vermindert werden können. In diesem Projekt werden daher verschiedene Codieraspekte untersucht und im Hinblick auf die vorkommenden Projektionen bei Ultraweitwinkel- und 360°-Videodaten optimiert. Ein spezieller Fokus liegt dabei auf der projektionsbasierten Bewegungskompensation, sowie der Intraprädiktion.

Screen Content Codierung
Screen Content Codierung basierend auf maschinellem Lernen und statistischer Modellierung
| Ihr Ansprechpartner |
| Hannah Och, M.Sc. |
| E-Mail: hannah.och@fau.de |
| Link zur Person |
In den letzten Jahren erfährt die Verarbeitung von sogenanntem screen content immer mehr Aufmerksamkeit. Screen Content steht dabei für Bilder, welche typischerweise auf Displays von Arbeitsplatzrechnern, Smartphones oder Ähnlichem zu sehen sind. Dabei sind die statistischen Eigenschaften von Screen-Content-Bildern oder Sequenzen sehr divers. Solche Bilder enthalten im Allgemeinen ’synthetische‘ Bildinhalte, nämlich Strukturen wie Buttons, Grafiken, Diagramme, Symbole, Texte, usw., welche besonders durch zwei bedeutende Eigenschaften gekennzeichnet sind: eine begrenzte Auswahl an Farben sowie sich wiederholende Muster. Neben den genannten Strukturen sind jedoch auch ’natürliche‘ Inhalte in Screen-Content inbegriffen, etwa Fotos und Videosequenzen, medizinische Aufnahmen oder computergenerierte fotorealistische Animationen. Anders als synthetische Aufnahmen sind diese durch unregelmäßige Farbverläufe und einen gewissen Rauschanteil gekennzeichnet. Screen Content ist typischerweise eine Mischung aus natürlichem und synthetischen Inhalten. Die Übertragung eben solcher Bildern und Sequenzen wird für eine Vielzahl von Anwendungen benötigt, wie etwa Screen Sharing, Cloud Computing oder Gaming.
Allerdings stellt Screen Content für herkömmliche Codierungsverfahren eine Herausforderung dar, da diese auf natürliche Inhalte optimiert sind und deshalb Screen-Content nicht effizient komprimieren können. Daher konzentriert sich dieses Projekt auf Weiterentwicklung und Testung einer neuen Kompressionsmethode für verlustlose und nahezu-verlustlose bzw. verlustbehafteter Kompression von Screen-Content-Inhalten. Ein besonderer Schwerpunkt wird dabei auf eine Kombination von maschinellem Lernen und statistischer Modellierung gelegt.